사용자가 웹브라우저에 주소를 입력하면 브라우저에 캐시에 있는 도메인과 연결된 서버의 주소를 찾는다
없으면 DNS로 요청을 해서 서버의 주소를 가져온다
서버의 주소로 요청을 보낸 후 응답을 받는다.
응답을 토대로 브라우저가 화면을 렌더링 해준다.
데이터 베이스
위의 흐름에서 데이터베이스는 웹 서버와 통신을 한다.
비관계형 데이터베이스는 4가지로 분류된다.
키-밸류 저장소 ( etcd )
그래프 저장소
칼럼 저장소
문서 저장소 ( 몽고 )
비관계형 데이터베이스는 조인 을 지원하지 않는다.
비관계형 데이터베이스가 바람직한 경우
아주 낮은 응답 지연시간이 요구되는 경우
다루는 데이터가 비정형 이라 관계형 데이터가 아님
데이터 (JSON, YAML, XML 등) 를 직렬화 하거나 역직렬화 할수 있기만 하면 됨
아주 많은 양의 데이터를 저장할 필요가 있음
수직적 규모 확장 vs 수평적 규모 확장
스케일 업과 스케일 아웃
스케일 업
한대의 서버에 CPU나 메모리를 증설하는 방식
스케일 아웃
서버를 여러대 추가하여 로드밸런스로 연결시키는 방식
스케일업의 단점
무한대로 CPU와 메모리를 증설할 수 없다.
자동복구 ( failover ) 방안이나 다중화 방안을 제시하지 않는다.
서버에 장애가 발생하면 웹이나 앱이 완전히 죽는다.
로드밸런서
부하분산집합에 속한 웹 서버들에게 트래픽 부하를 고르게 분산하는 역할
로드밸런서는 처음 흐름과 다르게 도메인 주소와 연결된게 웹서버의 IP가 아닌 로드밸런서의 공개 IP 주소와 연결된다.
더 나은 보안을 위해 서버간 통신( 로드밸런서와 서버)에는 사설 IP주소가 이용된다.
데이터베이스 다중화
보통 서버사이에 master서버와 slave서버 관계를 설정하고 데이터 원본은 master에 저장하고 사본은 slave에 저장하는 방식이다.
write operation ( 쓰기 연산) 은 마스터에만 지원한다.
슬레이브는 마스터로부터 사본을 전달받으며 읽기 연산만 지원한다
데이터베이스를 변경하는 명령어들 가령 insert, delete, update 등은 주 데이터베이스로만 전달되어야 한다.
대부분의 애플리케이션은 읽기 연산의 비중이 매우 높다.
그래서 슬레이브 서버를 많이두고 마스터서버를 적게 둔다.
장점
더 나은 성능
master-slave 다중화 모델에서 모든 데이터 변경 연산은 주 데이터베이스 서버로만 전달되는 반면 읽기 연산은 부 데이터베이스 서버들로 분산된다.
병렬로 처리될수 있는 쿼리의 수가 늘어나므로 성능이 좋아진다.
안전성
디비 서버 중 몇개가 파괴되어도 데이터는 보존된다.
가용성
디비의 데이터를 여러지역에 복제해둠으로써 하나의 디비서버에서 장애가 일어나도 다른 서버에 있는 데이터를 가져와 계속 서비스할 수 있게 된다.
시나리오
부 서버가 한대뿐인데 다운됐을 경우
읽기 연산이 모두 마스터 디비로 전달
즉시 새로운 슬레이브 디비 서버가 장애난 슬레이브 서버 디비를 대체
부 서버가 여러대인데 그중 한대가 다운됐을 경우
읽기 연산이 나머지 슬레이브 디비로 분산되며
새로운 슬레이브 디비 서버가 장애난 슬레이브 디비서버를 대체
주 디비서버가 다운되면
부 디비서버가 한개일 경우
슬레이브 서버중 한대가 새로운 마스터 서버가 될것이며 모든 디비 연산은 일시적으로 새로운 마스터 서버에서 수행된다.
그리고 새로운 슬레이브 서버가 추가된다.
하지만 이런 경우 부 서버에 보관된 데이터가 최신 상태가 아닐 수 있기 때문에 복구 스크립트를 돌려서 추가 해야 한다.
다중 마스터나 원형 다중화 방식을 도입하면 이런 상황에 대처하는데 도움이 될수도 있지만
해당 구성은 훨씬 복잡하다.
캐시
캐시는 값비싼 연산 결과 또는 자주 참조되는 데이터를 메모리 안에 두고 뒤이은 요청이 보다 빨리 처리될 수 있도록 하는 저장소다.
애플리케이션의 성능은 데이터 베이스를 얼마나 자주 호출하느냐에 크게 좌우되는데 캐시는 그런 문제를 완화할 수 있다.
캐시계층
데이터가 잠시 보관되는 곳으로 데이터베이스보다 훨씬 빠르다.
별도의 캐시 계층을 두면 성능이 개선될 뿐 아니라 데이터베이스의 부하를 줄일수 있고
별도의 캐시 계층을 두면 성능이 개선될 뿐 아니라 데이터베이스의 부하를 줄일 수 있고 캐시 계층의 규모를 독립적으로 확장시키는것도 가능해 진다.
요청받은 웹 서버는 캐시에 응답이 저장되어 있는지를 본다.
만일 저장되어 있다면 해당 데이터를 클라이언트에 반환한다.
없는 경우 데이터베이스에 쿼리를 날린 후 데이터를 찾아 캐시에 저장한 뒤 클라이언트에 반환한다.
이러한 캐시 전략을 읽기 주도형 캐시 전략 이라고 부른다.
다양한 캐시전략이 있는데 캐시할 데이터 종류, 크기, 액세스 패턴에 맞는 캐시전략을 선택하면 된다.
캐시 서버를 이용하는 방법은 간단한데 대부분의 캐시 서버들이 일반적으로 널리 쓰이는 프로그래밍 언어로 API를 제공하기 때문이다.
캐시 사용시 유의할 점
캐시는 어떤 상황에서 바람직 한가 ?
데이터 갱신은 자주 일어나지 않지만 참조는 빈번하게 일어난다면 바람직하다.
어떤 데이터를 캐시에 두어야 하는가?
캐시는 데이터를 휘발성 메모리에 두므로 영속적으로 보관할 데이터를 캐시에 두는 것은 바람직 하지 않ㄴ다.
예를 들어 캐시 서버가 재 시작되면 캐시 내의 모든 데이터는 사라진다.
중요한 데이터는 여전히 지속적 저장소(persistent data store)에 두어야 한다.
캐시에 보관된 데이터는 어떻게 만료 되는가 ?
이에 대한 정책을 마련해 두는것은 좋은 습관이다.
만료된 데이터는 캐시에서 삭제되어야 한다.
만료 정책이 없으면 데이터는 캐시에 계속 남게 된다.
만료 기한은 너무 짧으면 곤란한데 데이터베이스를 너무 자주 읽게 될것이기 떄문이다.
너무 길어도 곤란한데 원본과 차이날 가능성이 높아지기 때문이다.
일관성은 어떻게 유지되는가 ?
일관성은 데이터 저장소의 원본과 캐시 내의 사본이 같은지 여부다.
저장소의 원본을 갱신하는 연산과 캐시를 갱신하는 연산이 단일 트랜잭션으로 처리되지 않는 경우 이 일관성은 깨질수 있다.
여러 지역에 걸쳐 시스템을 확장해 나가는 경우 캐시와 저장소 사이에 일관성을 유지하는것은 어려운 문제다
장애에는 어떻게 대처할 것인가 ?
캐시 서버를 한대만 두는 경우 해당 서버는 단일 장애 지점이 되어버릴 가능성이 있다.
단일 장애 지점 이란?
어떤 특정 지점에서의 장애가 전체 시스템의 동작을 중단시켜버릴 수 있는 경우 우리는 해당 지점을 단일 장애 지점이라고 부른다.
단일 장애 지점을 피하려면 여러지역에 캐시 서버를 분산시켜야 한다.
캐시 메모리는 얼마나 크게 잡을 것인가 ?
캐시 메모리가 너무 작으면 액세스 패턴에 따라서는 데이터가 너무 자주 캐시에서 밀려나버려 ( eviction ) 캐시의 성능이 떨어지게 된다.
이를 막을 한가지 방법은 캐시 메모리를 과할당 하는것이다.
이렇게 하면 캐시에 보관될 데이터가 갑자기 늘어났을 때 생길 문제도 방지할 수 있게 된다.
데이터 방출 ( eviction ) 정책은 무엇인가 ?
캐시가 꽉 차버리면 추가로 캐시에 데이터를 넣어야 할 경우 기존 데이터를 내보내야 한다.
이것을 캐시 데이터 방출 정책이라 하는데 가장 널리 쓰이는 것은 마지막으로 사용된 시점이 가장 오래된 데이터를 내보내는 정책이다.
다른 정책으로는 사용빈도가 가장 낮은 데이터를 내보내는 정책이다
FIFO 같은 것도 있으며 경우에 맞게 적용 가능하다.
CDN
정적 콘텐츠를 전송하는 데 쓰이는 지리적으로 분산된 서버의 네트워크이다.
이미지, 비디오, CSS, javascript 파일 등을 캐시할 수 있다.
어떤 사용자가 웹사이트를 방문하면 그 사용자에게 가장 가까운 CDN서버가 정적 콘텐츠를 전달하게 된다.
직관적으로도 당연하겠지만 사용자가 CDN 서버로부터 멀면 멀수록 웹사이트는 천천히 로드될 것이다.
동작
사용자 A가 이미지 URL을 이용해 image.png에 접근한다.
URL의 도메인은 CDN 사업자가 제공한 것
CDN 서버의 캐시에 해당하는 이미지가 없는경우, 서버는 원본 서버에 요청하여 파일을 가져온다. 원본서버는 웹서버일수도 있고 아마존 S3와 같은 온라인 저장소 일수도 있다.
원본 서버가 파일을 CDN서버에 반환한다. 응답의 HTTP 헤더에는 해당 파일이 얼마나 오래 캐시될 수 있는지를 설명하는 TTL 값이 들어 있다.
CDN 서버는 파일을 캐시하고 사용자 A에게 반환한다. 이미지는 TTL에 명시된 시간이 끝날때 까지 캐시된다.
사용자 B가 같은 이미지에 대한 요청을 CDN 서버에 전송한다.
만료되지 않은 이미지에 대한 요청은 캐시를 통해 처리된다.
CDN 사용시 고려해야할 사항
비용
CDN은 보통 서드파티에 의해 운영되며 CDN 이용자는 CDN으로 들어가고 나가는 데이터 전송 양에 따라 요금을 내게 된다.
자주 사용되지 않는다면 CDN에서 제외하도록 하자.
적절한 만료 시한 설정
시의성이 중요한 컨텐츠의 경우 만료 시점을 잘 정해야한다. 너무 길지도 짧지도 않아야 하는데
너무 길면 컨텐츠의 신선도가 떨어지고 너무 짧으면 원본 서버에 번번히 접속하게 되어서 좋지 않다.
CDN 장애에 대한 대처 방안
CDN 자체가 죽었을 경우 웹사이트/애플리케이션이 어떻게 동작해야 하는지 고려한다.
가령 일시적으로 CDN이 응답하지 않더라도 해당 문제를 감지하여 원본 서버로부터 직접 컨텐츠를 가져오도록 클라이언트를 구성하는 것이 필요할 수도 있다.
컨텐츠 무효화
아직 만료되지 않은 컨텐츠라 하더라도 아래 방법 가운데 하나를 쓰면 CDN에서 제거할 수 있다.
CDN서비스 사업자가 제공하는 API를 이용하여 컨텐츠 무효화
컨텐츠의 다른 버전을 서비스 하도록 오브젝트 버저닝 이용
컨텐츠의 새로운 버전을 지정하기 위해서는 URL 마지막에 버전 번호를 인자로 주면 된다.
예를 들어 image.png?v=2와 같은 방식이다.
CDN 사용시 변화된 부분
더이상 정적 컨텐츠를 웹서버를 통해 서비스 하지 않는다.
캐시가 DB부하를 줄여준다.
무상태 웹 계층
웹 계층을 수평적으로 확장하기 위해서는 상태정보 ( 사용자 세션 데이터와 같은)를 웹 계층에서 제거하여야 한다.
바람직한 전략은 상태 정보를 RDB나 noSql같은 지속성 저장소에 보관하고 필요할 때 가져오도록 하는것이다.
이렇게 구성된 웹 계층을 무상태 웹 계층이라 부른다.
상태 정보 의존적인 아키텍처
상태 정보를 보관하는 서버는 클라이언트 정보 즉 상태를 유지하여 요청들 사이에 공유되도록 한다.
무상태 서버와는 반대
로드밸런서 사용시 사용자 정보를 가지고 있는 서버에 접속해야 상태정보가 유지된다.
로드밸런서가 이를 지원하기 위해 고정 세션(stickey session)이라는 기능을 제공하는데
이는 로드밸런서에 부담을 준다.
게다가 로드밸런서 뒷단에 서버를 추가하거나 제거하기도 까다로워진다.
이들 서버의 장애를 처리하기도 복잡하다.
무상태 아키텍처
무상태 아키텍처는 사용자로부터의 HTTP 요청은 어떤 웹서버로도 전달될 수 있다.
웹서버에서 상태정보가 필요할 경우 공유 저장소에서 데이터를 가져온다.
상태정보가 분리되어 있기때문에 구조가 단순하고 안정적이며 규모 확장이 쉽다.
이 공유 저장소는 rdb일수도 있고 멤캐시드나 레디스같은 캐시 시스템일수도 있고 nosql일수도 있다.
데이터 센터
장애가 없는 상황에서 사용자는 가장 가까운 데이터 센터로 안내되는데 통상 이 절차를 지리적 라우팅이라 부른다.
지리적 라우팅에서 geoDNS는 사용자의 위치에 따라 도메인 이름을 어떤 IP주소로 변환할지 결정할수 있도록 해주는 DNS 서비스다
로드밸런서에 의해 지리적 라우팅이 작동할수도 있고
다른 시스템에 의해 라우팅이 작동할수도 있다.
다중 데이터센터 아키텍처를 만드려면 몇가지 기술적 난제를 해결해야 한다.
트래픽 우회
올바른 데이터 센터로 트래픽을 보내는 효과적인 방법을 찾아야 한다.
GeoDNS는 사용자에게서 가장 가까운 데이터 센터로 트래픽을 보낼수 있도록 해준다.
데이터 동기화
데이터 센터마다 별도의 데이터베이스를 사용하기 때문에 장애가 자동으로 복구되어 트래픽이 다른 데이터베이스로 우회된다 해도 해당 데이터센터에는 찾는 데이터가 없을 수 있다.
이런 상황에서는 데이터를 여러 데이터센터에 걸쳐 다중화 하는것이다.
테스트와 배포
여러 데이터센터를 사용하도록 시스템이 구성된 상황이라면 웹 사이트 또는 애플리케이션을 여러 위치에서 테스트해보는것이 중요하다.
한편 자동화된 배포 도구는 모든 데이터센터에 동일한 서비스가 설치되도록 하는데 중요한 역할을 한다.
메시지 큐
메시지의 무손실을 보장하는 비동기 통신을 지원하는 컴포넌트
메시지의 버퍼 역할을 하며 비동기적으로 전송한다.
메시지 큐의 기본 아키텍처는 생산자 또는 발행자 ( 프로듀서/퍼블리셔 ) 라고 불리는 입력 서비스가 메시지를 만들어 메시지 큐에 발행한다.
큐에는 소비자 혹은 구독자 ( 컨슈머 / 섭스크라이버 ) 라고 불리는 서비스 혹은 서버가 연결되어 있는데 메시지를 받아 그에 맞는 동작을 수행하는 역할을 한다.
메시지 큐를 이용하면 서비스 또는 서버간 결합이 느슨해져서 규모 확장성이 보장되어야 하는 안정적 애플리케이션을 구성하기 좋다.
생산자는 소비자 프로세스가 다운되어 있어도 메시지를 발행할 수 있고, 소비자는 생산자 서비스가 가용한 상태가 아니더라도 메시지를 수신할 수 있다.
로그 메트릭 그리고 자동화
로그
에러 로그를 모니터링 하는것은 중요하다.
시스템의 오류와 문제를 쉽게 찾을 수 있기 때문
에러 로그를 서버단위로 모니터링 할 수도 있지만 로그를 단일 서비스로 모아주는 도구를 활용하면 더 편리하게 검색하고 조회할 수 있다.
메트릭
메트릭을 잘 수집하면 사업현황에 관한 유용한 정보도 얻고 시스템의 현재 상태를 손쉽게 파악할 수도 있다.
메트릭 가운데 유용한 메트릭 몇가지
호스트 단위 메트릭
CPU, 메모리, 디스크 I/O에 관한 메트릭이 여기 해당한다.
종합 메트릭
데이터베이스 계층의 성능, 캐시 계층의 성능 같은 것이 여기 해당한다.
핵심 비지니스 메트릭
일별 능동 사용자 ( daily active user ), 수익, 재방문 같은것이 여기 해당한다.
자동화
시스템이 크고 복잡해지면 생산성을 높이기 위해 자동화 도구를 활용해야 한다.
가령 지속적 통합을 도와주는 도구를 활용하면 개발자가 만드는 코드가 어떤 검증 절차를 자동으로 거치도록 할 수 있어서 문제를 쉽게 감지할 수 있다.
이외에도 빌드, 테스트, 배포 등의 절차를 자동화 할 수 있어서 개발 생산성을 크게 향상시킬수 있다.
데이터 베이스의 규모 확장
저장할 데이터가 많아지면 DB에 대한 부하도 증가한다.
그때가 오면 DB를 증설할 방법을 찾아야 한다.
규모확장에는 두가지가 있다.
수평적 확장, 수직적 확장
수직적 확장
스케일 업이라고 불리우며 서버의 사양을 고성능으로 증설하는 방법이다.
스택오버플로는 2013년 한해 동안 방문한 천만명의 사용자 전부 단 한대의 마스터 데이터베이스로 처리하였다.
하지만 수직적 접근법에는 약점이 있다.
무한히 서버의 사양을 증설할 수 없다.
SPOF
단일 실패지점이 될 확률이 크다.
단일실패지점: 실패했을경우 서버가 전부 멈춰버리는 지점
비용이 많이 든다.
수평적 확장
데이터베이스의 수평적 확장은 샤딩이라고 불리운다.
많은 서버를 추가함으로써 성능을 향상시킬수 있도록 한다.
샤딩은 대규모 데이터베이스를 샤드라고 부르는 작은 단위로 분할하는 기술을 일컫는다.
모든 샤드는 같은 스키마를 쓰지만 샤드에 보관되는 데이터사이에는 중복이 없다.
사용자 데이터를 어느 샤드에 넣을지는 사용자 ID에 따라 정한다.
예제는 사용자 아이디를 4로 나눈것을 해시함수로 사용하여 데이터가 보관되는 샤드를 정한다.
결과가 0이면 0번 샤드, 1이면 1번 샤드
샤딩 전략을 구현할 떄 고려해야 할 가장 중요한 것은 샤딩 키를 어떻게 정하느냐 하는것이다.
샤딩키는 파티션 키라고도 부르는데 데이터가 어떻게 분산될지 정하는 하나 이상의 칼럼으로 구성된다.
그럼 위의 예제 같은 경우 샤딩키는 사용자 ID 이다.
샤딩키를 통해 올바른 데이터베이스에 쿼리를 보내어 데이터 조회나 변경을 처리하므로 효율을 높일 수 있다.
샤딩은 디비 규모 확장을 실현하는 훌륭한 기술이지만 완벽하진 않다.
샤딩을 도입하면 시스템이 복잡해지고 풀어야할 문제도 늘어난다.
데이터의 재 샤딩
데이터가 너무 많아져서 하나의 샤드로는 더이상 감당하기 어려울 때
샤드간 데이터 분포가 균등하지 못하여 어떤 샤드에 할당된 공간 소모가 다른 샤드에 비해 빨리 진행될 때 ( 샤드 소진이라고 부른다 ) 이런 현상이 발생하면 샤드 키를 계산하는 함수를 변경하고 데이터를 재 배치 해야 한다. 안정 해시 기법을 활용하면 이 문제를 해결 할 수 있다.
셀레브리티 문제
핫스팟 키 문제라고도 부르는데 특정 샤드에 쿼리가 집중되어 서버에 과부하가 걸리는 문제다.
가령 자주 조회되는 데이터가 한 샤드에 몰려있다고 생각해보면 된다.
이럴 경우 샤드에는 읽기 연산 때문에 과부하가 걸리게 될것이다.
자주 접속되는 데이터를 균등하게 분배해야 할수도 있다. 아니면 각 샤드당 하나씩 분배해야 할수도 있다.
조인과 비정규화
하나의 디비를 여러 샤드 서버로 쪼개고 나면 여러 샤드에 걸친 데이터를 조인하기가 힘들어진다.
이를 해결하는 한 가지 방법은 디비를 비정규화하여 하나의 테이블에서 질의가 수행될수 있도록 하는 것이다.
Order에서 주문 정보를 가져와야하고 Product에서 상품이름을 가져와야하고 Member에서 회원 이름과 아이디를 가져와야 한다.
조회화면 특성상 빠를수록 좋은데 여러 애그리것에서 데이터를 가져와야 할 경우 구현 방법을 고민해봐야 한다.
3장에서 언급한 ID를 이용해서 애그리것을 참조하는 방식을 사용하면 즉시로딩 방식과 같은 JPA의 쿼리 관련 최적화 기능을 사용할 수 없다.
이는 한번의 select 쿼리로 조회화면에 필요한 데이터를 읽어올 수 없어 조회속도에 문제가 생길 수 있다.
애그리것간의 연관을 ID가 아니라 직접 참조하는 방식으로 연결해도 고민거리가 생긴다.
조회 화면의 특성에 따라 같은 연관도 즉시 로딩이나 지연 로딩으로 처리해야 하기 때문이다.
경우에 따라 DBMS가 제공하는 전용기능을 이용해 조회 쿼리를 작성해야 해서 JPA의 네이티브 쿼리를 사용해야 할 수도 있다.
이런 고민이 발생하는 이유는 시스템의 상태를 변경할 때와 조회할 때 단일 도메인 모델을 사용하기 떄문이다.
객체 지향으로 도메인 모델을 구현할 떄 주로 사용하는 ORM 기법은 Order.cancel()이나 Order.changeShippingInfo() 처럼 도메인의 상태를 변경하는데 적합하지만 주문 상세 조회화면 처럼 여러 애그리것에서 데이터를 가져와 출력하는 기능을 구현하기에는 고려할 것들이 많아서 구현을 복잡하게 만드는 원인이 된다.
이런 구현 복잡도를 낮추는 간단한 방법이 있는데 그것은 바로 상태변경을 위한 모델과 조회를 위한 모델을 분리하는 것이다.
CQRS
시스템이 제공하는 기능은 크게 두가지로 나누어 생각할수 있다.
하나는 상태를 변경하는 것이고 하나는 상태 정보를 조회하는 것이다.
도메인 모델 관점에서 상태 변경은 주로 한 애그리것의 상태를 변경한다.
예를 들어 주문 취소 기능과 배송지 정보 변경 기능은 한 개의 Order 애그리것을 변경한다.
반면에 조회 기능은 한 애그리것의 데이터를 조회할 수도 있지만 두개이상의 애그리것에서 데이터를 조회할수도 있다. ( 앞에서 얘기함 주문 상세정보조회 )
단일 모델로 두 종류 ( 상태 변경, 상태 조회 ) 의 기능을 구현하면 모델이 불필요하게 복잡해진다.
이럴때 CQRS를 사용하여 복잡도를 해결한다.
CQRS는 상태를 변경하는 명령 모델과 상태를 제공하는 조회 모델을 분리하는 패턴이다.
CQRS는 복잡한 도메인에 적합하다.
도메인이 복잡할수록 명령기능과 조회 기능이 다루는 데이터 범위에 차이가 발생하는데 이 두기능을 단일 모델로 처리하면 조회 기능의 로딩속도를 위해 모델 구현이 필요이상으로 복잡해지는 문제가 발생한다.
예를 들어 온라인 쇼핑에서 다양한 차원에서 주문/판매 통계를 조회해야 한다고 해보자.
JPA기반의 단일 도메인 모델을 사용하면 통계값을 빠르게 조회하기 위해 JPA와 관련된 다양한 성능관련 기능을 모델에 적용해야 한다.
이런 도메인에 CQRS를 적용하면 통계를 위한 조회 모델을 별도로 만들기 때문에 조회 떄문에 도메인이 복잡해지는 것을 막을 수 있다.
CQRS를 사용하면 각 모델에 맞는 구현 기술을 선택할 수 있다.
예를 들어, 명령 모델은 객체 지향에 기반해서 도메인 모델을 구현하기에 적당한 JPA를 사용해서 구현하고, 조회 모델은 DB 테이블에서 SQL로 데이터를 조회할 떄 좋은 MyBatis를 사용해서 구현할수 있다.
보통 결제 시스템은 외부에 존재하므로 RefundService는 외부의 환불 시스템 서비스를 호출하는데, 이때 두 가지 문제를 발생한다.
첫 번째 문제는 외부 서비스가 정상이 아닐경우 트랜잭션 처리를 어떻게 해야할지 애매하다는것
환불처리중 익셉션이 생겼을 경우 롤백을 해야하는가 안해야 하는가 ?
무조건 롤백이라고 생각할수 있지만 주문은 취소상태로 변경하고 환불만 나중에 다시 시도하는 방식으로 처리할 수 있다.
두번째는 성능에 관한 문제
외부시스템의 응답이 길어지면 그만큼 대기 시간이 발생한다.
환불 처리기능이 30초 걸리면 주문 취소 기능은 30초+@가 된다.
즉, 외부 서비스 성능에 직접적인 영향을 받는 문제가 있다.
두가지 문제 외에 도메인 객체에 서비스를 전달하면 추가로 설계상 문제가 나타날 수 있다.
주문 로직과 결제 로직이 섞이는 문제가 있다.
Order는 주문을 표현하는 도메인인데 결제 도메인의 환불 관련 로직이 섞이게 된다.
의존성이 생겨 변경시 같이 변경해야되는 문제가 발생함.
또하나의 문제는 기능을 추가할 때 발생한다.
만약 주문을 취소한 뒤에 환불뿐만 아니라 취소했다는 내용을 통지해야 한다면 ?
환불 도메인 서비스와 동일하게 파라미터로 통지 서비스를 받도록 구현하면 앞서 언급한 로직이 섞이는 문제가 더 커지고 트랜잭션 처리가 더 복잡해진다.
게다가 영향을 주는 외부서비스가 두개나 증가해버렸다.
지금까지 언급한 문제가 발생하는 이유는 주문 Bounded Context와 결제 Bounded Context 간의 강결합 때문이다.
주문이 결제와 강하게 결합되어 있어서 주문 Bounded Context가 결제 Bounded Context에 영향을 받는것이다.
이러한 결합을 없애는 방법이 있는데 그것은 바로 이벤트를 사용하는 것이다.
특히 비동기 이벤트를 사용하면 두 시스템 간의 결합을 크게 낮출 수 있다.
이벤트 개요
여기서 말하는 이벤트란 "과거에 벌어진 어떤 것" 을 의미한다.
예를 들어 사용자가 비밀번호를 변경한 것을 "암호를 변경했음 이벤트" 라고 부를 수 있다.
주문을 취소했다면 ? "주문을 취소했음 이벤트"
이벤트가 발생한다는 것은 상태가 변경됐다는 것을 의미한다.
이벤트는 발생한 것에서 끝나지 않는다.
이벤트가 발생하면 그 이벤트에 반응하여 원하는 동작을 수행하는 기능을 구현한다.
도메인 모델에서도 UI 컴포넌트와 유사하게 도메인의 상태 변경을 이벤트로 표현 할수있다.
이벤트 관련 구성 요소
도메인 모델에서 이벤트 주체는 엔티티, 밸류, 도메인 서비스와 같은 도메인 객체이다.
이들 도메인 객체는 도메인 로직을 실행해서 상태가 바뀌면 관련 이벤트를 발생한다.
이벤트 핸들러는 이벤트 생성 주체가 발생한 이벤트에 반응 한다.
이벤트 핸들러는 생성 주체가 발생한 이벤트를 전달받아 이벤트에 담긴 데이터를 이용해서 원하는 기능을 실행한다.
예를 들어 주문이 취소됐을 경우 "주문 취소됨 이벤트"를 받는 이벤트 핸들러는 해당 주문의 주문자에게 SMS로 주문 취소 사실을 통지할 수 있다.
이벤트 생성 주체와 이벤트 핸들러를 연결해 주는것이 이벤트 디스패처이다.
이벤트 생성 주체는 이벤트를 생성해서 디스패처에 이벤트를 전달한다.
이벤트를 전달받은 디스패처는 해당 이벤트를 처리할 수 있는 핸들러에 이벤트를 전파한다.
이벤트 디스패처의 구현 방식에 따라 이벤트 생성과 처리를 동기나 비동기로 실행하게 된다.
이벤트의 구성
이벤트는 발생한 이벤트에 대한 정보를 담는다.
이벤트 종류: 클래스 이름으로 이벤트 종류를 표현
이벤트 발생 시간
추가 데이터: 주문번호, 신규 배송지 정보등 이벤트와 관련된 정보
public class ShippingInfoChangedEvent {
private String orderNumber;
private long timestamp;
private ShippingInfo newShippingInfo;
// 생성자, getter
}
클래스이름을 과거형으로 했다 과거에 벌어진것을 표현하기 떄문에 이름에는 과거형을 사용한다.
public class Order {
public void changeShippingInfo(ShippingInfo newShippingInfo) {
verifyNotYetShipped();
setShippingInfo(newShippingInfo);
Events.raise(new ShippingInfoChangedEvent(number, newShippingInfo));
}
...
}
위 이벤트를 발생시킨 주체는 Order 애그리것이다.
Order 애그리것의 배송지 변경 기능을 구현한 메서드는 다음 코드처럼 배송지 정보를 변경한 뒤에 이벤트 디스패처를 이용해서 이벤트를 발생시킬 것이다.
public class ShippingInfoChangedHandler implement EventHandler<ShppingInfoChangedEvent> {
@Override
public void handle(ShppingInfoChangedEvent evt) {
shippingInfoSynchronizer.sync(
evt.getOrderNumber(),
evt,getNewShippingInfo();
)
}
}
...
변경된 배송지 정보를 물류 서비스에 재전송하는 핸들러는 다음과 같다.
ShippingInfoChangedEvent 를 처리하는 핸들러는 디스패처로부터 이벤트를 전달받아 필요한 작업을 수행한다.
이벤트는 이벤트 핸들러가 작업을 수행하는 데 필요한 최소한의 데이터를 담아야 한다.
이 데이터가 부족할 경우 핸들러는 필요한 데이터를 읽기 위해 관련 API를 호출하거나 DB에서 데이터를 직접 읽어와야 한다.
그렇다고 이벤트 자체와 관련 없는 데이터를 포함할 필요는 없다.
바뀐 배송지 정보를 포함하는 것은 맞지만 배송지 정보 변경과 관련없는 주문 상품번호와 개수를 담을 필요는 없다.
이벤트 용도
이벤트는 크게 두 가지 용도로 쓰인다.
첫번쨰는 트리거의 용도로 쓰이는데 도메인의 상태가 바뀔때 다른 후처리를 해야 할 경우 후처리를 실행하기 위한 트리거로 이벤트를 사용할 수 있다.
예매 결과를 SMS로 통지할 떄도 이벤트를 트리거로 사용할 수 있다.
예매 도메인은 예매 완료 이벤트를 발생시키고 이 이벤트 핸들러에서 SMS를 발송시키는 방식으로 구현
이벤트의 두번째 용도는 서로 다른 시스템간의 데이터 동기화이다.
배송지를 변경하면 외부 배송 서비스에 바뀐 배송지 정보를 전송해야 한다.
이 경우 주문 도메인은 배송지 변경 이벤트를 발생시키고 이벤트 핸들러는 외부 배송 서비스와 배송지 정보를 동기화 한다.
이벤트 장점
이벤트를 사용하면 첫장에서 말한 서로 다른 도메인 로직이 섞이는 것을 방지할 수 있다.
또한 기능 확장도 용이해진다. 구매 취소시 환불과 함께 이메일을 보내고 싶다면 이메일 발송을 처리하는 핸들러를 구현하고 디스패처에 등록하면 된다.
기능을 확장해도 도메인 로직은 수정할 필요가 없다.
이벤트, 핸들러, 디스패처 구현
이벤트와 관련된 코드는 다음과 같다.
이벤트 클래스
EventHandler: 이벤트 핸들러를 위한 상위 타입으로 모든 핸들러는 이 인터페이스를 구현한다.
Events: 이벤트 디스패처. 이벤트 발행, 이벤트 핸들러 등록, 이벤트를 핸들러에 등록하는 등의 기능을 제공한다.
이벤트 클래스
이벤트 자체를 위한 상위 타입은 존재하지 않는다. 원하는 클래스를 이벤트로 사용할 것이다.
이벤트클래스의 이름을 결정할때는 과거 시제를 사용해야 한다.
OrderCanceledEvent와 같이 클래스 이름뒤에 접미사로 Event를 사용해서 Event로 사용하는 클래스 라는것을 명시적으로 표현할 수 있고 OrderCanceld처럼 간결함을 위해 과거 시제만 사용할 수도 있다.
public class OrderCanceledEvent extends Event {
// 이벤트는 핸들러에서 이벤트를 처리하는 데 필요한 데이터를 포함한다.
private String orderNumber;
public OrderCanceledEvent(String number) {
super();
this.orderNumber = number;
}
public String getOrderNumber() { return orderNumber; }
}
이벤트클래스는 이벤트를 처리하는데 필요한 최소한의 데이터를 포함해야 한다.
public abstract class Event {
private long timestamp;
public Event() {
this.timestamp = System.currentTimeMillis();
}
public long getTimestamp() {
return timestamp;
}
}
모든 이벤트가 공통으로 갖는 프로퍼티가 존재한다면 관련 상위 클래스를 만들 수도 있다.
위와 같은 상위 클래스를 만들고 각 이벤트 클래스가 상속받도록 할 수 있다.
EventHandler 인터페이스
EventHandler 인터페이스는 이벤트 핸들러를 위한 상위 인터페이스이다.
public interface EventHandler<T> {
// handle 메서드를 이용해서 필요한 기능을 구현한다.
void handle(T event);
// 핸들러가 이벤트를 처리할 수 있는지 여부를 검사한다.
default boolean canHandle(Object event) {
Class<?>[] typeArgs = TypeResolver.resolveRawArguments(
EventHandler.class, this.getClass()
);
return typeArgs[0].isAssignableForm(event.getClass());
}
}
EventHandler 인터페이스를 상속받는 클래스는 handle() 메서드를 이용해서 필요한 내용을 구현하면 된다.
canHandler() 메서드는 핸들러가 이벤트를 처리할 수 있는지 여부를 검사한다.
Event의 타입이 T의 파라미터화 타입에 할당 가능하면 true를 리턴한다.
이벤트 디스패처인 Events 구현
public class CancelOrderService {
private OrderRepository orderRepository;
private RefundService refundService;
@Transactional
public void cancel(OrderNo orderNo) {
// handle 메서드에 전달한 EventHandler를 이용해서 이벤트를 처리하게 된다.
Events.handle(
(OrderCanceledEvent evt) -> refundService.refund(evt.getOrderNumber())
);
Order order = findOrder(orderNo);
order.cancel();
// ThreadLocal 변수를 초기화해서 OOME가 발생하지 않도록 한다.
Events.reset();
}
}
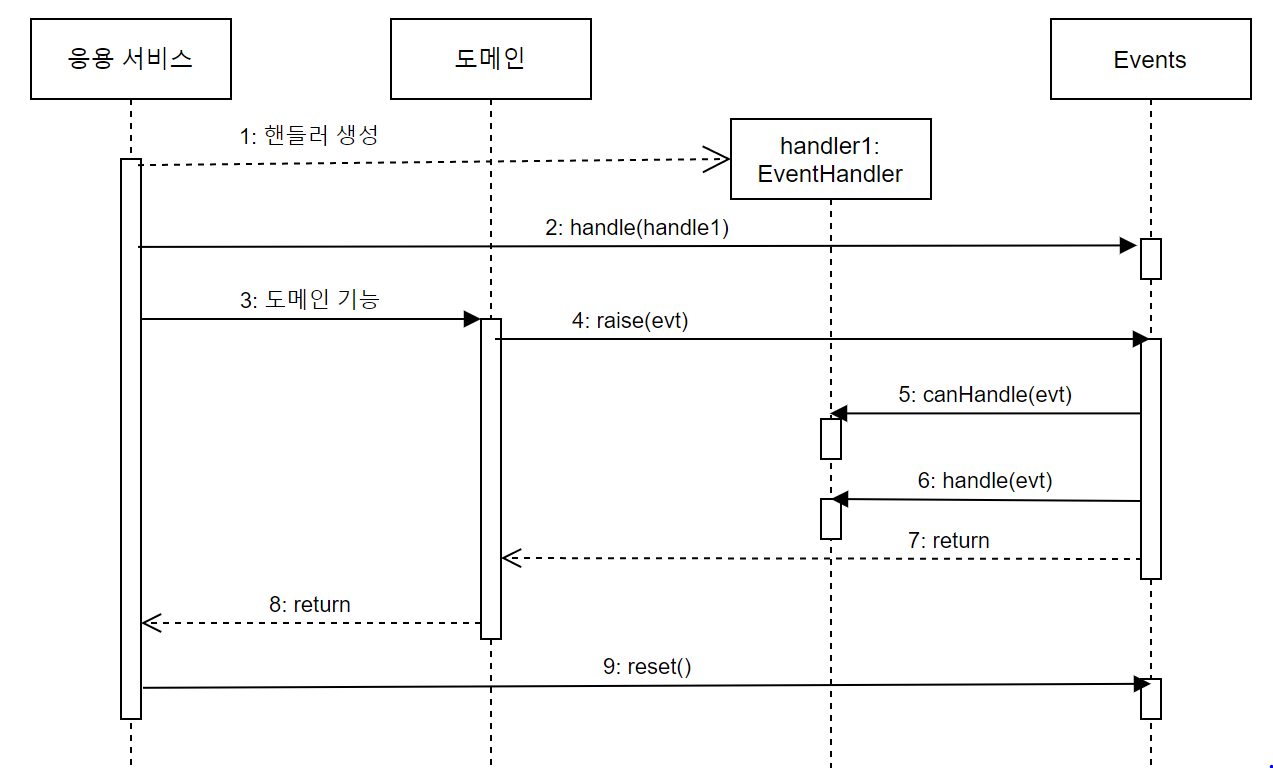
도메인을 사용하는 응용 서비스는 이벤트를 받아 처리할 핸들러를 Events.handle()로 등록하고 도메인 기능을 실행한다.
위 코드는 OrderCancledEvent가 발생하면 Events.handle() 메서드에 전달한 EventHandler를 이용해서 이벤트를 처리하게 된다.
이벤트가 발생하면 이벤트를 처리할 EventHandler를 list에서 찾아 EventHandler의 handle() 메서드를 호출해서 이벤트를 처리 한다.
public class Order {
public void cancel() {
verifyNotYetShipped();
this.state = OrderState.CANCELED;
Events.raise(new OrderCanceledEvent(number.getNumber()));
}
}
Events.raise()를 이용해서 이벤트를 발생시키면 Events.raise() 메서드는 이벤트를 처리할 핸들러를 찾아 handle() 메서드를 실행한다.
public class Events {
// EventHandler 목록을 보관하는 ThreadLocal 변수를 생성한다.
private static ThreadLocal<List<EventHandler<?>>> handlers =
new ThreadLocal<>();
// 이벤트를 처리 중인지 여부를 판단하는 ThreadLocal 변수를 생성한다.
private static ThreadLocal<Boolean> publishing =
new ThreadLocal<Boolean>() {
@Override
protected Boolean initialValue() {
return Boolean.FALSE;
}
};
// 파라미터로 전달받은 이벤트를 처리한다.
public static void raise(Object event) {
// 이벤트를 처리 중이면 진행하지 않는다.
if (publishing.get()) return;
try {
// 이벤트 처리 중 상태를 true로 변경한다.
publishing.set(Boolean.TRUE);
// handlers에 담긴 EventHandler가 파라미터로 전달받은 이벤트를 처리할 수 있는지 확인하고
List<EventHandler<?>> eventHandlers = handlers.get();
if (eventHandlers == null) return;
for (EventHandler handler: eventHandlers) {
// handlers에 담긴 EventHandler가 파라미터로 전달받은 이벤트를 처리할 수 있는지 확인한다.
if (handler.canHandle(event)) {
// 처리 가능하면 핸들러의 handle() 메서드에 이벤트 객체를 전달한다.
handler.handle(event);
}
}
} finally {
// 핸들러의 이벤트 처리가 끝나면 처리 중 상태를 False로 변경한다.
publishing.get(Boolean.FALSE);
}
}
// 이벤트 핸들러를 등록하는 메서드
public static void handle(EventHandler<?> handler) {
// 이벤트를 처리 중이면 등록하지 않는다.
if (publishing.get()) return;
List<EventHandler<?>> eventHandlers = handlers.get();
if (eventHandlers == null) {
eventHandlers = new ArrayList<>();
handlers.set(eventHandlers);
}
eventHandlers.add(handler);
}
// handlers에 보관된 List 객체를 삭제한다.
public static void reset() {
if (!publishing.get()) {
handlers.remove();
}
}
}
public class Order {
public void cancel() {
verifyNotYetShipped();
this.state = OrderState.CANCELED;
Events.raise(new OrderCanceledEvent(number.getNumber()));
}
}
Events는 핸들러 목록을 유지하기 위해 ThreadLocal 변수를 사용한다.
톰캣과 같은 웹 애플리케이션 서버는 스레드를 재사용하므로 ThreadLocal에 보관한 값을 제거하지 않으면 기대했던것과 다르게 코드가 동작할수 있다.
예를 들어 사용자의 요청을 처리한 뒤 Events.reset()을 실행하지 않으면 스레드 handlers가 담고 있는 List에 계속 핸들러 객체가 쌓이게 되어 결국 메모리 부족 에러가 발생하게 된다.
따라서 이벤트 핸들러를 등록하는 응용 서비스는 다음과 같이 마지막에 Events.reset() 메서드를 실행해야 한다.
Events.raise()는 등록된 핸들러의 canHandle()를 이용해서 이벤트를 처리할수 있는지 확인
핸들러가 처리할 수 있다면 handle()메서드를 이용해서 이벤트를 처리
Events.raise() 실행을 끝내고 리턴
도메인 기능 실행을 끝내고 리턴
Events.reset()를 이용해서 ThreadLocal을 초기화 한다
코드 흐름을 보면 응용 서비스와 동일한 트랜잭션 범위에서 핸들러의 handle()이 실행되는것을 알수 있다.
즉 도메인의 상태변경과 이벤트 핸들러는 같은 트랜잭션 범위에서 실행된다.
AOP를 이용한 Events.reset() 실행
응용 서비스가 끝나면 ThreadLocal에 등록된 핸들러 목록을 초기화 하기 위해
Events.reset() 메서드를 실행한다.
모든 응용 서비스마다 메서드 말미에 Events.reset()을 실행하는 코드를 넣는것은 중복에 해당한다.
이런 류의 중복을 없앨 떄 적합한 것이 바로 AOP다.
코드는 아래와 같다.
@Aspect
// 우선순위를 0으로 지정한다. 이를 통해 트랜잭션 관련 AOP보다 우선순위를 높여 이 AOP가 먼저 적용되도록 한다.
@Order(0)
@Component
public class EventsResetProcessor {
//서비스 메서드의 중첩 실행 개수를 저장하기 위한 ThreadLocal 변수를 생성한다.
private ThreadLocal<Integer> nestedCount = new ThreadLocal<Integer>() {
@Override
protected Integer initialValue() {
return new Integer(0);
}
};
// @Around Aspect를 이용해서 AOP를 구현한다.
// 적용 대상은 com.myshop 패키지 및 그 하위 패키지에 위치한 @Service가 붙은 빈 객체다
@Around(
"@target(org.springframework.stereotype.Service) and within(com.myshop..*)")
public Object doReset(ProceedingJoinPoint joinPoint) throws Throwable {
// 중첩 실행 횟수를 1 증가한다.
nestedCount.set(nestedCount.get() + 1);
try {
// 대상 메서드를 실행한다.
return joinPoint.proceed();
} finally {
// 중첩 실행 횟수를 1 감소한다.
nestedCount.set(nestedCount.get() - 1);
// 중첩 실행횟수가 0이면 Events.reset()을 실행한다.
if (nestedCount.get() == 0) {
Events.reset();
}
}
}
}
Service 애노테이션을 이용해서 응용 서비스를 지정했는데 @Service를 사용하지 않을 경우
@Around의 포인트 컷에 @Target대신 execution() 명시자를 사용해도 된다.
public class LockId {
private String value;
public LockId(String value) {
this.value = value;
}
public String getValue() {
return value;
}
}
@RequestMapping("/some/edit/{id}")
public String editForm(@PathVariable("id") Long id, ModelMap model) {
// 1. 오프라인 선점 잠금 시도
LockId lockId = lockManager.tryLock("data", id);
// 2. 기능 실행
Data data = someDao.select(id);
model.addAttribute("data", data);
// 3. 잠금 해제에 사용할 LockId를 모델에 추가
model.addAttribute("lockId", lockId);
return "editForm";
}
잠금을 해제할 경우 전달받은 LockId를 이용한다.
잠금시 반드시 주어진 lockId를 갖는 잠금이 유효한지 검사해야한다.
잠금의 유효 시간이 지났으면 이미 다른 사용자가 잠금을 선점한다.
잠금을 선점하지 않은 사용자가 기능을 실행했다면 기능 실행을 막아야 한다.
DB를 이용한 LockManager 구현
잠금 정보를 저장할 테이블과 인덱스를 생성한다.
쿼리는 MySQL용
CREATE TABLE LOCKS (
`type` varchar(255),
id varchar(255),
lockid varchar(255),
expiration_time datetime,
primary key (`type`, id)
) character set utf8;
스레드1이 먼저 커밋시도, 이 시점에 애그리것의 버전은 5지만 스레드1이 수정에 성공하고 버전은 6이 된다.
스레드1이 트랜잭션을 커밋한 후에 스레드2가 커밋을 시도하는데 이미 애그리것 버전이 6이므로 스레드2는 데이터 수정에 실패하게 된다.
JPA는 버전을 이용한 비선점 잠금 기능을 지원한다.
@Entity
@Table(name = "purchage_order")
@Access(AccessType.FIELD)
public class Order {
@EmbeddedId
private OrderNo number;
@Version
private long version;
...
}
JPA는 엔티티가 변경되어 UPDATE 쿼리를 실행할때 @Version에 명시한 필드를 이용해서 비선점 잠금 쿼리를 실행한다.
즉 애그리것 객체의 버전이 10이면 UPDATE쿼리를 실행할때 아래와 같은 쿼리를 실행한다
UPDATE purchage_order SET ..., version = version + 1
WHERE number = ? and version = 10
응용서비스는 버전에 대해 알 필요가 없다.
리포지토리에서 필요한 애그리것을 구하고 알맞은 기능만 실행하면 된다.
기능을 실행하는 과정에서 애그리것의 데이터가 변경되면 JPA는 트랜잭션 종료 시점에 비선점 잠금을 위한 쿼리를 실행한다.
public class ChangeShippingService {
private OrderRepository orderRepository;
@Transactional
public void changeShipping(ChangeShippingRequest changeReq) {
Order order = orderRepository.findById(new OrderNo(changeReq.getNumber()));
checkNoOrder(order);
order.changeShippingInfo(changeReq.getShippingInfo());
}
...
}
비선점 잠금을 위한 쿼리를 실행할 때 쿼리 실행 결과로 수정된 행의 개수가 0이면 이미 누군가 앞서 데이터를 수정한 것이다.
이는 트랜잭션이 충돌한 것이므로 트랜잭션 종료 시점에 익셉션이 발생한다.
위 코드의 경우 스프링의 @Transactional을 이용해서 트랜잭션 범위를 정했으므로 changeShipping() 메서드가 리턴될때 트랜잭션이 종료되고 이시점에 트랜잭션 충돌이 발생하면 OptimisticLockingFailureException을 발생시킨다.
표현 영역의 코드는 이 익셉션의 발생 여부에 따라 트랜잭션 충돌이 일어났는지 확인할 수 있다.
@Controller
public class OrderController {
...
@RequestMapping(value = "/changeShipping", method = RequestMethod.POST)
public String changeShipping(ChangeShippingRequest changeReq) {
try {
changeShippingService.changeShipping(changeReq);
return "changeShippingSuccess";
} catch(optimisticLockingFailureException ex) {
// 누군가 먼저 같은 주문 애그리거트를 수정했으므로,
// 트랜잭션 충돌이 일어났다는 메시지를 보여준다.
return "changeShippingExConflic";
}
}
비선점 잠금을 확장해서 적용할 수 있다.
시스템은 사용자에게 수정 폼을 제공할 때 애그리것 버전을 함꼐 전송하고 사용자가 폼을 전송할 때와 폼을 생성할 때 사용한 애그리것 버전을 함께 전송하도록 할 수 있다.
시스템을 애그리것을 수정할 때 사용자가 전송한 버전과 애그리것 버전이 동일한 경우에만 수정 기능을 수행하도로 함으로써 트랜잭션 충돌문제를 해소할 수 있다.
위의 과정2에서 운영자는 배송 상태 변경을 요청할 때 앞서 과정 1을 통해 받은 애그리것의 버전값을 함께 전송한다.
시스템은 애그리것을 읽는데 해당 시점의 버전 값도 함께 읽어온다. 만약 과정 1에서 받은 버전 A와 과정 2.1을 통해 읽은 애그리것의 버전 B가 다르면 과정 1과 과정 2 사이에 다른 사용자가 해당 애그리것을 수정한 것이다.
이 경우 시스템은 운영자가 이전 데이터를 기준으로 작업을 요청한 것으로 간주하여 과정 2.1.2와 같이 수정할 수 없다는 에러를 응답으로 전송한다.
만약 A와 B의 버전이 같다면 과정 1과 과정 2 사이에 아무도 애그리것을 수정하지 않은것이므로 이 경우 시스템은 과정 2.1.3과 같이 애그리것을 수정하고 과정 2.1.4를 이용해서 변경 내용을 DBMS에 반영한다.
과정 2.1.1과 과정 2.1.4사이에 아무도 애그리것을 수정하지 않았다면 커밋에 성공하므로 성공 결과를 응답으로 전송한다.
반면에 과정 2.1.1과 과정 2.1.4사이에 누군가 애그리것을 수정해서 커밋했다면 버전값이 증가한 상태가 되므로 트랜잭션 커밋에 실패하고 결과로 에러 응답을 전송한다.
위와 같이 비선점 잠금 방식을 여러 트랜잭션으로 확장하려면 애그리것 정보를 뷰로 보여줄때 버전 정보도 함께 사용자 화면에 전달해야 한다.
HTML 폼을 생성하는 경우 버전 값을 갖는 hidden 타입 (input) 태그를 생성해서 폼 전송 시 버전 값이 서버에 함께 전달되도록 한다.
사용자 요청을 처리하는 응용서비스를 위한 요청 데이터는 사용자가 전송한 버전값을 포함한다.
예를 들어, 배송 상태 변경을 처리하는 응용 서비스가 전달받는 데이터는 다음과 같이 주문 번호와 함께 해당 주문을 조회한 시점의 버전 값을 포함해야 한다.
public class StartShippingRequest {
private String orderNumber;
private long version;
protected StartShippingRequest() {}
public StartShippingRequest(String orderNumber, long version) {
this.orderNumber = orderNumber;
this.version = version;
}
public String getOrderNumber() {
return orderNumber;
}
public long getVersion() {
return version;
}
}
응용서비스는 전달받은 버전 값을 이용해서 애그리것의 버전과 일치하는지 확인하고 일치하는 경우에만 요청한 기능을 수행한다.
@Service
public class StartShippingService {
private OrderRepository orderRepository;
@Transactional
public void startShipping(StartShippingRequest req) {
Order order = orderRepository.findById(new OrderNo(req.getOrderNumber()));
checkNoOrder(order);
if (!order.matchVersion(req.getVersion())) {
// throw new VersionConflictException();
throw new OptimisticLockingFailureException("version conflict");
}
order.startShipping();
}
@Autowired
public void setOrderRepository(OrderRepository orderRepository) {
this.orderRepository = orderRepository;
}
}
버전이 맞지않으면 표현 계층으로 exception 을 전달한다.
@Controller
public class OrderAdminController {
private StartShippingService startShippingService;
@RequestMapping(value = "/startShipping", method = RequestMethod.POST)
public String startShipping(StartShippingRequest startReq) {
try {
startShippingService.startShipping(startReq);
return "shippingStarted";
} catch(OptimisticLockingFailureException | VersionConflictException ex) {
// 트랜잭션 충돌
return "startShippingTxConflict";
}
}
...
표현 계층에서 익셉션을 받아 처리한다.
VersionConflictException은 응용 서비스코드에서 발생시키고 OptimisticLockingFailureException 는 스프링에서 발생시킨다.
버전 충돌상황에 대한 구분이 명시적으로 필요 없다면 응용 서비스에서 프레임워크용 익셉션을 발생시켜도 된다.














Uploaded by Notion2Tistory v1.1.0